Text analytics
The analysis of text data gives useful insigths. This post uses news group data set to investigate text data

Processing large amounts text data is an important area in natural language processing. The analysis of text data with machine learning tools can give us important insights. Given a text data such as a book, posts or tweets, one may ask questions such as list of common words.
In this post we are going to analyse 20 news groups dataset. The Newsgroups dataset comprises around 18000 newsgroups posts on 20 topics. The dataset can by obtained by using fetch_20newsgroups in sklearn.datasets as fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'), shuffle=True, random_state=42)
1: First step is to get the dataset and look into it to get understanding about how it is organized…
from sklearn.datasets import fetch_20newsgroups
newsgroups_full = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'), shuffle=True, random_state=42)
print(newsgroups_full.keys())## dict_keys(['data', 'filenames', 'target_names', 'target', 'DESCR'])The newsgroups_full dataset has properties and function such as keys() which important keys for fetching the details of different types.
For example target_names specifies various names of the newsgroups, target is 20 different unique index corresponding to target_names
the key data is used to get actual data stored in different files having some filenames. Lets see how go use different keys
# The target names are the names of the news groups
print(newsgroups_full.target_names)## ['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']# The data is actual data stred as list
print(newsgroups_full.target_names[newsgroups_full.target[1]])## comp.sys.ibm.pc.hardwareprint(newsgroups_full.data[1])## My brother is in the market for a high-performance video card that supports
## VESA local bus with 1-2MB RAM. Does anyone have suggestions/ideas on:
##
## - Diamond Stealth Pro Local Bus
##
## - Orchid Farenheit 1280
##
## - ATI Graphics Ultra Pro
##
## - Any other high-performance VLB card
##
##
## Please post or email. Thank you!
##
## - MattAs we can se the above two statements give us the data about post belonging to comp.sys.ibm.pc.hardware which contains:
# Putting the words in the dictionary
newsgroups_full_dnry = dict()
for ind in range(len(newsgroups_full.data)):
grp_name = newsgroups_full.target_names[newsgroups_full.target[ind]]
if grp_name in newsgroups_full_dnry:
newsgroups_full_dnry[grp_name] += 1
else:
newsgroups_full_dnry[grp_name] = 1
print("Total number of articles in dataset " + str(len(newsgroups_full.data))) ## Total number of articles in dataset 18846print("Number of articles category wise: ")## Number of articles category wise:print(newsgroups_full_dnry)## {'rec.sport.hockey': 999, 'comp.sys.ibm.pc.hardware': 982, 'talk.politics.mideast': 940, 'comp.sys.mac.hardware': 963, 'sci.electronics': 984, 'talk.religion.misc': 628, 'sci.crypt': 991, 'sci.med': 990, 'alt.atheism': 799, 'rec.motorcycles': 996, 'rec.autos': 990, 'comp.windows.x': 988, 'comp.graphics': 973, 'sci.space': 987, 'talk.politics.guns': 910, 'misc.forsale': 975, 'rec.sport.baseball': 994, 'talk.politics.misc': 775, 'comp.os.ms-windows.misc': 985, 'soc.religion.christian': 997}Pie chart of distribution of the articles
import matplotlib.pyplot as plt
labels = newsgroups_full.target_names
slices = []
for key in newsgroups_full_dnry:
slices.append(newsgroups_full_dnry[key])
fig , ax = plt.subplots()
ax.pie(slices, labels = labels , autopct = '%1.1f%%', shadow = True, startangle = 90)
ax.axis("equal")
ax.set_title("News groups messages distribution")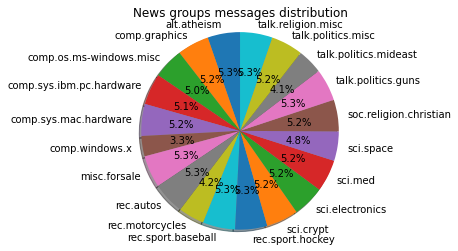
The distribution of messages posted in different newsgroups is almost similar. The sports groups have most number of messages
Viewing the data as tabular form. We can put the data in the dataframe and see the top ten records
import pandas as pd
data_labels_map = dict(enumerate(newsgroups_full.target_names))
message, target_labels, target_names = (newsgroups_full.data, newsgroups_full.target, [data_labels_map[label] for label in newsgroups_full.target])
newsgroups_full_df = pd.DataFrame({'text': message, 'source': target_labels, 'source_name': target_names})
print(newsgroups_full_df.shape)## (18846, 3)newsgroups_full_df.head(10)## text ... source_name
## 0 \n\nI am sure some bashers of Pens fans are pr... ... rec.sport.hockey
## 1 My brother is in the market for a high-perform... ... comp.sys.ibm.pc.hardware
## 2 \n\n\n\n\tFinally you said what you dream abou... ... talk.politics.mideast
## 3 \nThink!\n\nIt's the SCSI card doing the DMA t... ... comp.sys.ibm.pc.hardware
## 4 1) I have an old Jasmine drive which I cann... ... comp.sys.mac.hardware
## 5 \n\nBack in high school I worked as a lab assi... ... sci.electronics
## 6 \n\nAE is in Dallas...try 214/241-6060 or 214/... ... comp.sys.mac.hardware
## 7 \n[stuff deleted]\n\nOk, here's the solution t... ... rec.sport.hockey
## 8 \n\n\nYeah, it's the second one. And I believ... ... rec.sport.hockey
## 9 \nIf a Christian means someone who believes in... ... talk.religion.misc
##
## [10 rows x 3 columns]2: Next step is cleaning the text…
To clean the large amounts of text we use nltk tools such as WordNetLemmatizer, PorterStemmer, stopwords, names.
Lets import them first
import nltk
from nltk.corpus import names
from nltk.stem import WordNetLemmatizer
from nltk.stem import PorterStemmer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import re
stopWords = set(stopwords.words('english'))
validwords = set(nltk.corpus.words.words())re is regular expression library in python. We need to first define few functions such as text_tokenizer. The main aim is to clean the posts first by removing the alpha-numeric, numeric and non-alphabatic characters then by applying stemming and lemmmatizing techiniques so that we are left with only the words which are meaningful for the analysis. Lets write the functions for the same
porter_stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
def text_tokenizer(str_input):
words = re.sub(r"[^A-Za-z\-]", " ", str_input).lower().split()
words = [porter_stemmer.stem(word) for word in words if len(word) > 2 ]
words = [lemmatizer.lemmatize(word) for word in words if len(word) > 2 and word in validwords and word not in stopWords]
return ' '.join(words)2.1: Next is to apply text_tokenizer function to get a new column having clean text…
newsgroups_full_df['clean_text'] = newsgroups_full_df.text.apply(lambda x: text_tokenizer(x))
newsgroups_full_df.sort_values(by=['source'],inplace=True)
newsgroups_full_df.head(5)## text ... clean_text
## 8501 \nI could give much the same testimonial about... ... could give much scout back gay thank well put ...
## 14285 \nFine... THE ILLIAD IS THE WORD OF GOD(tm) (... ... fine word god matter prove wrong west
## 17533 Hello Gang,\n\nThere have been some notes rece... ... hello gang note recent ask obtain fish questio...
## 1527 \n Sorry, gotta disagree with you on this one... ... one bill prefer half bake bob vice said queen ...
## 14271 The latest news seems to be that Koresh will g... ... latest news seem give finish write sequel
##
## [5 rows x 4 columns]2.3:Creating a dictionary of newsgroup cleaned text
wordlst = list()
newsgroup_dic = dict()
label = ''for i in range(0,20):
newsgroups_full_df_1 = newsgroups_full_df.loc[newsgroups_full_df['source'] == i]
for row in newsgroups_full_df_1[['source_name', 'clean_text']].iterrows():
r = row[1]
label = r.source_name
wordlst.append(''.join(map(str,r.clean_text)))
wordstr = ' '.join(map(str, wordlst))
newsgroup_dic[label] = wordstr
label = ''
wordstr = ''
wordlst.clear() Next steps will create the features out of the dictionary of the newsgroups words just created in the previous steps. In natural language processing feature extraction is an important step. In this case the words themselves becomes the features. To extract the features python provides an important library called CountVectorizer. We need to transform our cleaned_text using sklearn.feature_extraction.text and CountVectorizer library. Lets apply it to our newsgroup data.
3: Feature extraction…
The feature vector can be created with sklearn CountVectorizer. When creating the feature vectors we can decide the number of features, as well as set limits for the minimum and maximum number of documents a word can appear.
Note that the transformed data is stored in a sparse matrix (which is much more efficient for large data sets).
# First lets import it
from sklearn.feature_extraction.text import CountVectorizer
count_vectorizer = CountVectorizer(stop_words = 'english')The function get_word_freq_dict_sorted returns a sorted dictionary of words counts. It taks a dataframe as its argument.
def get_word_freq_dict_sorted(ng_X_df):
wordfreq = ng_X_df.sum(axis=0)
features = ng_X_df.columns.tolist()
counts = wordfreq.tolist()
wordfreq_df = pd.DataFrame()
wordfreq_df['word'] = features
wordfreq_df['count'] = counts
wordfreq_dict = dict(wordfreq_df.values.tolist())
wordfreqdict_sorted = dict(sorted(wordfreq_dict.items(), key=lambda x: x[1],reverse=True))
return wordfreqdict_sortedNow iterate over the newsgroup dictionary obtained from the newsgroups dataframe and create another dictionary where keys are the newsgroups and values are another dictionary of word counts in that newsgroup.
ng_dict_of_words = dict()
for key in newsgroup_dic:
ng_X = count_vectorizer.fit_transform([newsgroup_dic[key]])
ng_X_df = pd.DataFrame(ng_X.toarray(), columns=count_vectorizer.get_feature_names())
ng_dict_of_words[key] = get_word_freq_dict_sorted(ng_X_df)
4: Exploring words in the news groups..
QUESTION: What are the top words in newsgroup comp.sys.ibm.pc.hardware by their count ?
ANSWER: Iterating over the dictionary corresponding to comp.sys.ibm.pc.hardware we get the top ten words as {space orbit launch use like time mission year earth moon}. Like wise we get the most common words in each newsgroup by their count.
word_dic = ng_dict_of_words['comp.sys.ibm.pc.hardware']
word_df = pd.DataFrame.from_dict(word_dic, orient='index')
print(word_df.T.iloc[0:1,0:10])## drive use card ani control disk work problem know ide
## 0 990 792 537 476 441 384 369 356 333 309Various other approaches to explore words in news groups include graphical methods, which help us visualize the distribution of words across news groups. We can use matplotlib.pyplot to draw differnt graphs.
Next we will explore various algorithms for text classification.
5 Text Classification…
Text classification is done using various machine learning algorithms. The most popular ones are
- MultinomialNB
- LogisticRegression
- SVC
The goal of the text classification is to predict which newsgroup a post belongs to based on the post text.
BOW and TF-IDF are two different techniques for text classification
Bag of Words (BoW) is an algorithm that counts frequency of a word in newsgroups. Those word counts allow us to compare different newsgroups and gauge their similarities for applications like search, topic modeling etc.
In TF-IDF, words are given weight. TF-IDF measures relevance, not frequency. That is, wordcounts are replaced with TF-IDF scores across the whole dataset.
To use text classification algorithm we need to randomly separates data into training and testing dataset and fit the classifier with selected training data. A classifer defines model for text classification. The score gives us the accuracy for testing data.
Different classifiers can give us different results for accuracy. Accuracy depends on the specific problem, number of categories and differences between them, etc.
6 Evaluation…
Evaluation of the model can be done using the confusion matrix which can be ploted using the heatmap plot. A basic heatmap is shown below

newgroupsheatmap.png
The confusion matrix depicts the wrongly classified records. For example 4 articles from comp.graphics are wrongly classified as comp.windows.x.
***7 Slide show
knitr::include_url('/slides/NewsGroupsAnalysis.html')Summary: Text classifcation has usefull applications in detection of spam pages, personal email sorting, tagging products or document filtering, automatic classification of the text based on its contents, sentiment analysis etc. There are different methods and models availble in sklearn and nltp libraries in python which can be utilized for text classification and natural language processing applications.


